TL;DR You can offload CPU intensive code using Node’s worker threads module. A demo app of the effect of this can be found here.
I thought I understood Node’s async mode. I’ve used callbacks, I’ve used promises and I’ve used async/await. I’ve dealt with unhandled promise rejections and I’ve worked out how to use try and catch with async tasks.
I thought I’d mastered the async model before and been rudely awakened by some unexpected behaviour. It has been a long time since one of those rude awakenings and by now I thought I really had mastered async.
How wrong I was.

I have a simple web application that takes a lot of complex database records; processes those records; and then outputs them.
The processing is pretty intensive and exponentially more work as the number of records increases – i.e. a time complexity of O(n²).
The application became unresponsive whilst this processing was happening, which was not a massive surprise. There are a pair loops doing a lot of stuff.
I thought that I could just slap a few async / awaits into my code at various points and turn my synchronous code into asynchronous code. Node just works like magic, doesn’t it?
It didn’t work.

My understanding now is that Node can actually only do few very select types of operation asynchronously. These are operations for which Node has specifc addons – notably network operations, I/O and cryptography. Any module that ultimate uses those operations will also benefit from using async / await.
Running async / await on synchronous code doesn’t achieve anything.
Reading this excellent article, I realised I could do something with setImmediate, but I didn’t like the code impact. I like my code to look like and read like what it is doing. If I insert setImmediate() function calls at various points, it just looks confusing to me.
Some further research brought me to another excellent article and to Node’s worker threads, standard as of version 11.
Before worker threads, there were other options, but worker threads brings the capability into Node’s core modules.
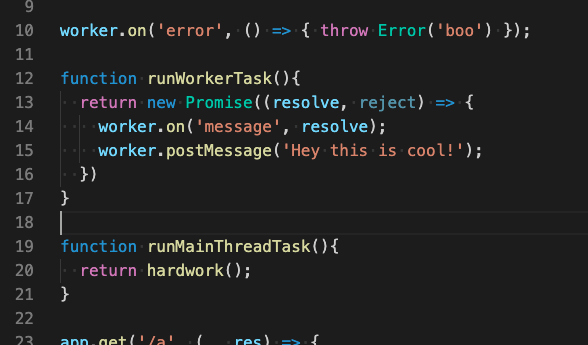
Using worker threads effectively gives you places where you can run your CPU intensive code without affecting (well, not significantly affecting) the performance of your main application.
My understanding is that worker threads share the same memory as the main application, which means you don’t get the memory hit of forking child processes.
Worker threads are also relatively easy to work with. You can pass data backwards and forwards between the main thread and the worker threads. The data doesn’t need to be serialised, so performance is pretty good and the code looks clean.
In my, currently limited, experience, the only real issue is that you cannot pass functions from the main thread to a worker thread. For me this would be a killer feature as the worker code could be super generic. As it is, I’ve written a worker wrapper for any code that I want to execute in this way.
I still want to find out whether it is better to create on worker per task or create a single worker that processes multiple tasks. The latter seems more scalable but perhaps requires additional work to ensure data integrity across multiple tasks.
You can read more about Node threads here.
For sharing large amounts of data, I understand that sharedArrayBuffers might also be helpful.
I’ve created a git repo to demonstrate the difference between running a CPU intensive task on the main thread and on a worker thread. You can find that repo here.
Once installed, run npm test to see the demo. The test script calls one ‘ping’ endpoint once per second and then runs a CPU heavy task (a big loop) once on a worker thread and once on the main thread.
When run on the main thread, the ping requests are ignored until the task is completed – a delay of around 5 seconds in this demo.
Conversely, the worker thread completes the same task but doesn’t block the ping requests.
If you want me to look into any other tech subjects, please contact me on Twitter: @damien_hampton.